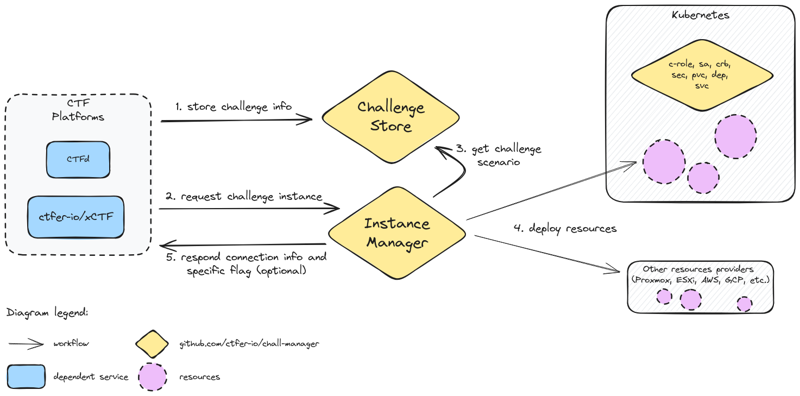
Chall-Manager solves the Challenge on Demand problem through a generalization technically based upon Pulumi, and embodies the State-of-the-Art Continuous Deployment practices.
Chall-Manager is a MicroService whose goal is to manage challenges and their instances.
Each of those instances are self-operated by the source (either team or user) which rebalance the concerns to empowers them.
It eases the job of Administrators, Operators, Chall-Makers and Players through various features, such as hot infrastructure update, non-vendor-specific API, telemetry and scalability.
Thanks to a generic Scenario concept, the Chall-Manager could be operated anywhere (e.g. a Kubernetes cluster, AWS, GCP, microVM, on-premise infrastructures) and run everything (e.g. containers, VMs, IoT, FPGA, custom resources).
¹ We do not harden the configuration in the installation script, but recommend you digging into it more as your security model requires it (especially for production purposes).
² Autoscaling is possible with an hypervisor (e.g. Docker Swarm).
Kubernetes
Note
We highly recommend the use of this deployment strategy.
This deployment strategy guarantee you a valid infrastructure regarding our functionalities and security guidelines.
Moreover, if you are afraid of Pulumi you’ll have trouble creating scenarios, so it’s a good place to start !
The requirements are:
a distributed block storage solution such as Longhorn, if you want replicas.
# Get the repository and its own Pulumi factorygit clone git@github.com:ctfer-io/chall-manager.git
cd chall-manager/deploy
# Use it straightly !# Don't forget to configure your stack if necessary.# Refer to Pulumi's doc if necessary.pulumi up
Now, you’re done !
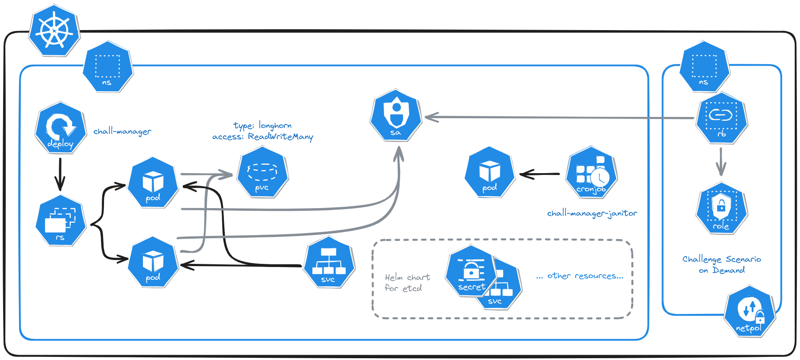
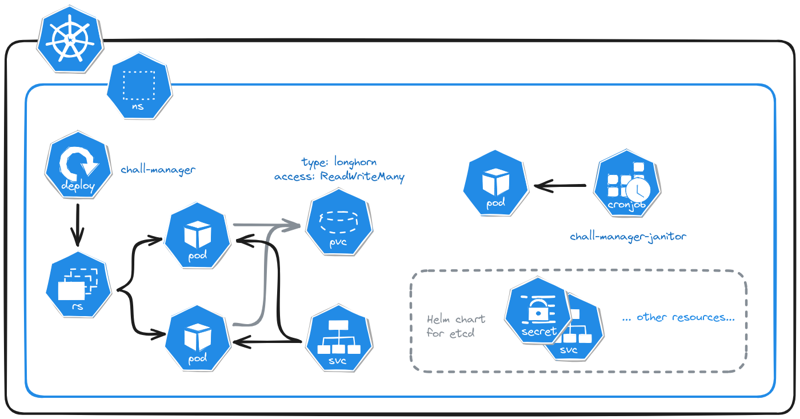
Micro Services Architecture of chall-manager deployed in a Kubernetes cluster.
Binary
Security
We highly discourage the use of this mode for production purposes, as it does not guarantee proper isolation.
The chall-manager is basically a RCE-as-a-Service carrier, so if you run this on your host machine, prepare for dramatic issues.
To install it on a host machine as systemd services and timers, you can run the following script.
curl -fsSL https://github.com/ctfer-io/chall-manager/blob/main/hack/setup.sh | sh
If you are unsatisfied of the way the binary install works on installation, unexisting update mecanisms or isolation, the Docker install may fit your needs.
To deploy it using Docker images, you can use the official images:
What are the signals to capture once in production, and how to deal with them ?
Once in production, the chall-manager provides its functionalities to the end-users.
But production can suffer from a lot of disruptions: network latencies, interruption of services, an unexpected bug, chaos engineering going a bit too far…
How can we monitor the chall-manager to make sure everything goes fine ?
What to monitor to quickly understand what is going on ?
Metrics
A first approach to monitor what is going on inside the chall-manager is through its metrics.
Warning
Metrics are exported by the OTLP client.
If you did not configure an OTEL Collector, please refer to the deployment documentation.
Name
Type
Description
challenges
int64
The number of registered challenges.
instances
int64
The number of registered instances.
You can use them to build dashboards, build KPI or anything else.
They can be interesting for you to better understand the tendencies of usage of chall-manager through an event.
Tracing
A way to go deeper in understanding what is going on inside chall-manager is through tracing.
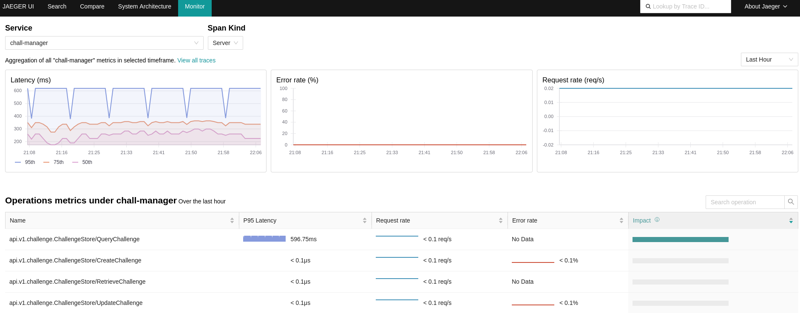
First of all, it will provide you information of latencies in the distributed locks system and Pulumi manipulations. Secondly, it will also provide you Service Performance Monitoring (SPM).
Using the OpenTelemetry Collector, you can configure it to produce RED metrics on the spans through the spanmetrics connector.
When a Jaeger is bound to both the OpenTelemetry Collector and the Prometheus containing the metrics, you can monitor performances AND visualize what happens.
An example view of the Service Performance Monitoring in Jaeger, using the OpenTelemetry Collector and Prometheus server.
Through the use of those metrics and tracing capabilities, you could build alerts thresholds and automate responses or on-call alerts with the alertmanager.
A reference architecture to achieve this description follows.
graph TD
subgraph Monitoring
COLLECTOR["OpenTelemetry Collector"]
PROM["Prometheus"]
JAEGER["Jaeger"]
ALERTMANAGER["AlertManager"]
GRAFANA["Grafana"]
COLLECTOR --> PROM
JAEGER --> COLLECTOR
JAEGER --> PROM
ALERTMANAGER --> PROM
GRAFANA --> PROM
end
subgraph Chall-Manager
CM["Chall-Manager"]
CMJ["Chall-Manager-Janitor"]
ETCD["etcd cluster"]
CMJ --> CM
CM --> |OTLP| COLLECTOR
CM --> ETCD
end
You are a ChallMaker or only curious ?
You want to understand how the chall-manager can spin up challenge instances on demand ?
You are at the best place for it then.
First of all, you’ll configure your Pulumi factory.
The example below constitutes the minimal requirements, but you can add more configuration if necessary.
Pulumi.yaml
name:my-challengeruntime:godescription:Some description that enable others understand my challenge scenario.
Then create your entrypoint base.
main.go
packagemainimport("github.com/pulumi/pulumi/sdk/v3/go/pulumi")funcmain(){pulumi.Run(func(ctx*pulumi.Context)error{// Scenario will go there
returnnil})}
You will need to add github.com/pulumi/pulumi/sdk/v3/go to your dependencies: execute go mod tidy.
Starting from here, you can get configurations, add your resources and use various providers.
For this tutorial, we will create a challenge consuming the identity from the configuration and create an Amazon S3 Bucket. At the end, we will export the connection_info to match the SDK API.
main.go
packagemainimport("github.com/pulumi/pulumi-aws/sdk/v6/go/aws/s3""github.com/pulumi/pulumi/sdk/v3/go/pulumi""github.com/pulumi/pulumi/sdk/v3/go/pulumi/config")funcmain(){pulumi.Run(func(ctx*pulumi.Context)error{// 1. Load config
cfg:=config.New(ctx,"my-challenge")config:=map[string]string{"identity":cfg.Get("identity"),}// 2. Create resources
_,err:=s3.NewBucketV2(ctx,"example",&s3.BucketV2Args{Bucket:pulumi.String(config["identity"]),Tags:pulumi.StringMap{"Name":pulumi.String("My Challenge Bucket"),"Identity":pulumi.String(config["identity"]),},})iferr!=nil{returnerr}// 3. Export outputs
// This is a mockup connection info, please provide something meaningfull and executable
ctx.Export("connection_info",pulumi.String("..."))returnnil})}
Don’t forget to run go mod tidy to add the required Go modules. Additionally, make sure to configure the chall-manager pods to get access to your AWS configuration through environment variables, and add a Provider configuration in your code if necessary.
Tips & Tricks
You can compile your code to make the challenge creation/update faster, but chall-manager will automatically do it anyway to enhance performances (avoid re-downloading Go modules and Pulumi providers, and compile the scenario).
Such build could be performed through CGO_ENABLED=0 go build -o main path/to/main.go.
Add the following configuration in your Pulumi.yaml file to consume it, and set the binary path accordingly to the filesystem.
runtime:name:gooptions:binary:./main
You can test it using the Pulumi CLI with for instance the following.
pulumi stack init # answer the questionspulumi up # preview and deploy
Make it ready for chall-manager
Now that your scenario is designed and coded accordingly to your artistic direction, you have to prepare it for the chall-manager to receive it.
Make sure to remove all unnecessary files, and zip the directory it is contained within.
If you don’t pre-compiled your scenario, you need to archive all source files.
If you prebuilt the scenario, you’ll only need to pack the main binary and Pulumi.yaml file.
Use an additional configuration
Note
This section represents an advanced usage of the Chall-Manager scenario API.
It should not be used by a beginner.
A scenario can get provided additional configuration over a key=value map. Using this, you can further configure your scenario at last moment, or even reuse them.
For intance, if your challenge provide a configuration key=value pair for a Docker image to use, and your instance does too for an authorized CIDR, then you might reuse your scenario for multiple use cases.
To configure those values, please refer to the API documentation.
From the SDK point of view, you can access those additional configuration key=value pairs as follows.
main.go
packagemainimport("github.com/ctfer-io/chall-manager/sdk""github.com/pulumi/pulumi/sdk/v3/go/pulumi")funcmain(){sdk.Run(func(req*sdk.Request,resp*sdk.Response,opts...pulumi.ResourceOption)error{// 1. Get your additional configuration pairs
image,ok:=req.Config.Additional["image"]if!ok{returnmissing("image")}cidr,ok:=req.Config.Additional["cidr"]if!ok{returnmissing("cidr")}// 2. Use them
// ...
// 3. Return content as always
resp.ConnectionInfo=pulumi.String(string(b)).ToStringOutput()returnnil})}funcmissing(keystring)error{returnfmt.Errorf("missing additional configuration for %s",key)}
2.2 - Software Development Kit
Sometimes, you don’t need big things. The SDK makes sure you don’t need to be a DevOps.
When you (a ChallMaker) want to deploy a single container specific for each source, you don’t want to understand how to deploy it to a specific provider. In fact, your technical expertise does not imply you are a Cloud expert… And it was not to expect !
Writing a 500-lines long scenario fitting the API only to deploy a container is a tedious job you don’t want to do more than once: create a deployment, the service, possibly the ingress, have a configuration and secrets to handle…
For this reason, we built a Software Development Kit to ease your use of chall-manager.
It contains all the features of the chall-manager without passing you the issues of API compliance.
Additionnaly, we prepared some common use-cases factory to help you focus on your CTF, not the infrastructure:
The community is free to create new pre-made recipes, and we welcome contributions to add new official ones. Please open an issue as a Request For Comments, and a Pull Request if possible to propose an implementation.
Build scenarios
Fitting the chall-manager scenario API imply inputs and outputs.
Despite it not being complex, it still requires work, and functionalities or evolutions does not guarantee you easy maintenance: offline compatibility with OCI registry, pre-configured providers, etc.
Indeed, if you are dealing with a chall-manager deployed in a Kubernetes cluster, the ...pulumi.ResourceOption contains a pre-configured provider such that every Kubernetes resources the scenario will create, they will be deployed in the proper namespace.
Inputs
Those are fetchable from the Pulumi configuration.
the connection information, as a string (e.g. curl http://a4...d6.my-ctf.lan)
flag
❌
the identity-specific flag the CTF platform should only validate for the given source
Kubernetes ExposedMonopod
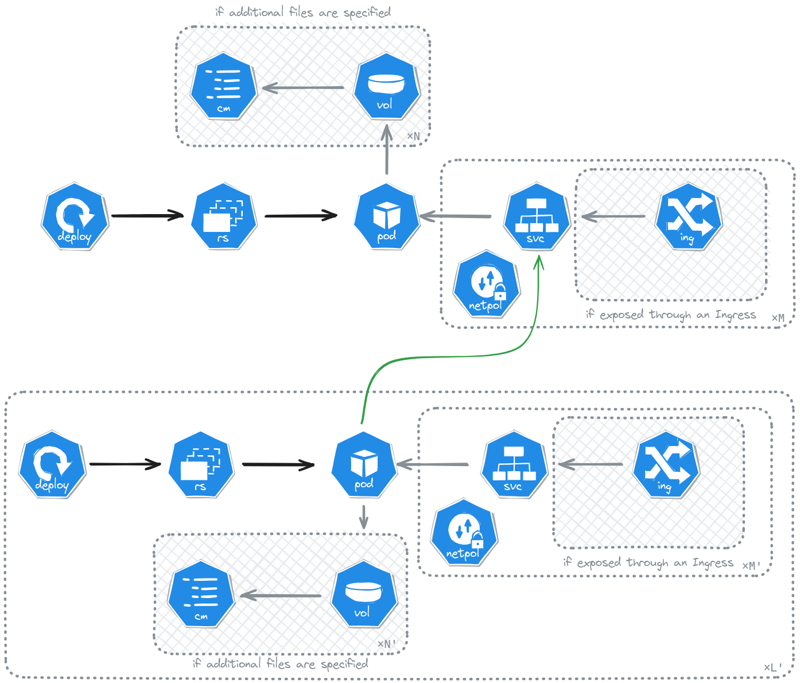
When you want to deploy a challenge composed of a single container, on a Kubernetes cluster, you want it to be fast and easy.
Then, the Kubernetes ExposedMonopod fits your needs ! You can easily configure the container you are looking for and deploy it to production in the next seconds.
The following shows you how easy it is to write a scenario that creates a Deployment with a single replica of a container, exposes a port through a service, then build the ingress specific to the identity and finally provide the connection information as a curl command.
To use ingresses, make sure your Kubernetes cluster can deal with them: have an ingress controller (e.g. Traefik), and DNS resolution points to the Kubernetes cluster.
The Kubernetes ExposedMonopod architecture for deployed resources.
Kubernetes ExposedMultipod
When you want to deploy multiple containers together (e.g. a web app with a frontend, a backend, a database and a cache), on a Kubernetes cluster, and want it to be fast and easy.
Then, the Kubernetes ExposedMultipod fits your needs ! Your can easily configure the containers and the networking rules between them so it deploys to production in the next seconds.
The following shows you how easy it is to write a scenario that creates multiple deployments, services, ingresses, configmaps, … and provide the connection information as a curl command.
To use ingresses, make sure your Kubernetes cluster can deal with them: have an ingress controller (e.g. Traefik), and DNS resolution points to the Kubernetes cluster.
The Kubernetes ExposedMultipod architecture for deployed resources.
The ExposedMultipod is a generalization of the ExposedMonopod with [n] containers. In fact, the later’s implementation passes its container to the first as a network of a single container.
2.3 - Update in production
How to update a challenge scenario once it is in production (instances are deployed) ?
So you have a challenge that made its way to production, but it contains a bug or an unexpected solve ?
Yes, we understand your pain: you would like to patch this but expect services interruption… It is not a problem anymore !
A common worklow of a challenge fix happening in production.
We adopted the reflexions of The Update Framework to provide infrastructure update mecanisms with different properties.
What to do
You will have to update the scenario, of course.
Once it is fixed and validated, archive the new version.
Then, you’ll have to pick up an Update Strategy.
Update Strategy
Require Robustness¹
Time efficiency
Cost efficiency
Availability
TL;DR;
Update in place
✅
✅
✅
✅
Efficient in time & cost ; require high maturity
Blue-Green
❌
✅
❌
✅
Efficient in time ; costfull
Recreate
❌
❌
✅
❌
Efficient in cost ; time consuming
¹ Robustness of both the provider and resources updates. Robustness is the capability of a resource to be finely updated without re-creation.
More information on the selection of those models and how they work internally is available in the design documentation.
You’ll only have to update the challenge, specifying the Update Strategy of your choice. Chall-Manager will temporarily block operations on this challenge, and update all existing instances.
This makes the process predictible and reproductible, thus you can test in a pre-production environment before production. It also avoids human errors during fix, and lower the burden at scale.
2.4 - Use the flag variation engine
Use the flag variation engine to block shareflag, as a native feature of the Chall-Manager SDK.
Shareflag is considered by some as the worst part of competitions leading to unfair events, while some others consider this a strategy.
We consider this a problem we could solve.
Context
In “standard” CTFs as we could most see them, it is impossible to solve this problem: if everyone has the same binary to reverse-engineer, how can you differentiate the flag per each team thus avoid shareflag ?
For this, you have to variate the flag for each source. One simple solution is to use the SDK.
Use the SDK
The SDK can variate a given input with human-readable equivalent characters in the ASCII-extended charset, making it handleable for CTF platforms (at least we expect it). If one character is out of those ASCII-character, it will be untouched.
To import this part of the SDK, execute the following.
go get github.com/ctfer-io/chall-manager/sdk
Then, in your scenario, you can create a constant that contains the “base flag” (i.e. the unvariated flag).
If you want to use decorator around the flag (e.g. BREFCTF{}), don’t put it in the flag constant else it will be variated.
3 - Developer Guides
A collection of guides made for the developers using the Micro Service.
3.1 - Extensions
How to extend chall-manager capabilities ?
How can we extend chall-manager capabilities ? You cannot, in itself: there is no support for live-mutability of functionalities, plugins, nor there will be (immutability is both an operation and security principle, determinism is a requirement).
But as chall-manager is designed as a Micro Service, you only have to reuse it !
Hacking chall-manager API
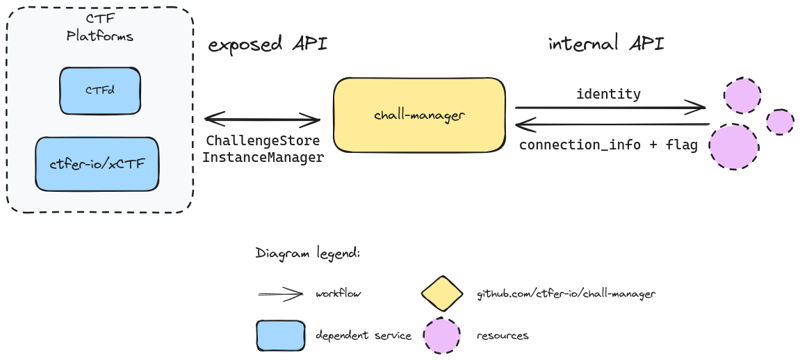
Taking a few steps back, you can abstract the chall-manager API to fit your needs:
the connection_info is an Output data from the instance to the player.
the flag is an optional Output data from the instance to the backend.
Then, if you want to pass additional data, you can use those commmunications buses.
Case studies
Follows some extension case studies.
MultiStep & MultiFlags
The original idea comes from the JointCyberRange, the following architecture is our proposal to solve the problem.
In the “MultiStep challenge” problem they would like to have Jeopardy-style challenges constructed as a chain of steps, where each step has its own flag. To completly flag the challenge, the player have to get all flags in the proper order. Their target environment is an integration in CTFd as a plugin, and challenges deployed to Kubernetes.
Deploying those instances, isolating them, janitoring if necessary are requirements, thus would have been reimplemented. But chall-manager can deploy scenarios to whatever environment.
Our proposal is then to cut the problem in two parts according to the Separation of Concerns Principle:
a CTFd plugin that implement a new challenge type, and communicate with chall-manager
chall-manager to deploy the instances
The connection_info can be unchanged from its native usage in chall-manager.
The flag output could contain a JSON object describing the flags chain and internal requirements.
Our suggested architecture for the JCR MultiStep challenge plugin for CTFd.
Through this architecture, JCR would be able to fit their needs shortly by capitalizing on the chall-manager capabilities, thus extend its goals.
Moreover, it would enable them to provide the community a CTFd plugin that does not only fit Kubernetes, thanks to the genericity.
3.2 - Integrate with a CTF platform
Tips, tricks and guidelines on the integration of Chall-Manager in a CTF platform.
So you want to integrate chall-manager with a CTF platform ? Good job, you are contributing to the CTF ecosystem !
the support of OpenTelemetry for distributed tracing.
Use the proto
The chall-manager was conceived using a Model-Based Systems Engineering practice, so API models (the contracts) were written, and then the code was generated.
This makes the .proto files the first-class citizens you may want to use in order to integrate chall-manager to a CTF platform.
Those could be found in the subdirectories here. Refer the your proto-to-code tool for generating a client from those.
If you are using Golang, you can directly use the generated clients for the ChallengeStore and InstanceManager services API.
If you cannot or don’t want to use the proto files, you can use the gateway API.
Use the gateway
Because some languages don’t support gRPC, or you don’t want to, you can simply communicate with chall-manager through its JSON REST API.
Chall-Manager has a gRPC+HTTP API, so you don’t have to update deployment to use it.
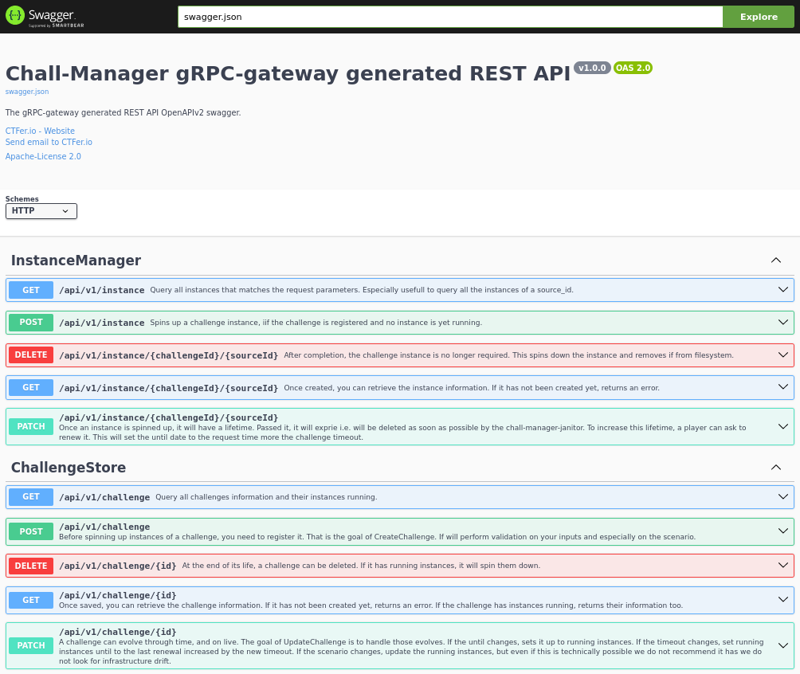
Nevertheless, for development purposes, we recommend you use the swagger that could be turned on with either --gw-swagger as an arg or GATEWAY_SWAGGER=true as a varenv.
You can then reach the Swagger at /swagger, which should show you the following.
The chall-manager REST JSON API Swagger.
Use this Swagger to understand the API, and build your language-specific client in order to integrate chall-manager.
We do not provide official language-specific REST JSON API clients.
4 - Design
Understand what led us to design Chall-Manager as such: what are the needs, what were the problems, how we solved them.
In this documentation chapter, we explain what led us to design the Chall-Manager as such.
We go from the CTF limitations, the Challenge on Demand problem, the functionalities, the genericity of our approach, how we made sure of its usability, to the innovative testing strategy.
4.1 - Context
Inform yourself on the context of the Challenge on Demand problem.
A Capture The Flag (CTF) is an event that brings a set of players together, to challenge themselves and others on domain-specific problems.
Those events could have for objective learning, or made for competing with cashprizes.
They could be hold physically, virtually or hybrid.
CTFs are largely adopted in the cybersecurity community, taking place all over the world on a daily basis.
In this community, plenty domains are played: web, forensic, Active Directory, cryptography, game hacking, telecommunications, steganography, mobile, OSINT, reverse engineering, programming, etc.
In general, a challenge is composed of a name, has a description, a set of hints, files and other data, shared for all. On top of those, the competition runs over points displayed on scoreboards: this is how people keep getting entertained throughout a continuous and hours-long rush.
Most of the challenges find sufficient solutions to their needs with those functionalities, perhaps some does not…
If we consider other aspects of cybersecurity -as infrastructures, telecommunications, satellites, web3 and others- those solutions are not sufficient.
They need specific deployments strategies, and are costfull to deploy even only once.
Nevertheless, with the emergence of the Infrastructure as Code paradigm, we think of infrastructures as reusable components, composing with pieces like for a puzzle. Technologies appeared to embrace this new paradigm, and where used by the cybersecurity community to build CTF infrastructures.
Players could then share infrastructures to play those categories.
In reality, yes they could. But, de facto, they share the same infrastructure. If you are using a CTF to select the top players for a larger event, how would you be able to determine who performed better ? How do you assure their success is due to their sole effort and not a side effect of someone else work ?
In the opposite direction, if you are a player who is loosing its mind on a challenge, you won’t be glad that someone broke the entire challenge thus your efforts are wortheless, isn’t it ?
What’s next ?
Read The Need to clarify the necessity of Challenge on Demand.
4.2 - The Need
Understand why it was a problem before chall-manager.
“Sharing is caring” they said… they were wrong.
Sometimes, isolating things can get spicy, but it implies replicating infrastructures. If someone soft-locks its challenge, it would be its entire problem: it won’t affect other players experience.
Furthermore, you could then imagine a network challenge where your goal is to chain a vulnerability to a Man-in-the-Middle attack to get access to a router and spy on communications to steal a flag ! Or a small company infrastructure that you would have to break into and get an administrator account !
And what if the infrastructure went down ? Then it would be isolated, other players could still play in their own environment.
This idea can be really productive, enhance the possibilities of a CTF and enable realistic -if not realism- attacks to take place in a controlled manner.
This is the Challenge on Demand problem: giving every player or team its own instance of a challenge, isolated, to play complex scenarios.
With a solution to this problem, players and teams could use a brand new set of knowledges they could not until this: pivoting from an AWS infrastructure to an on-premise company IT system, break into a virtual bank vault to squeeze out all the belongings, hack their own Industrial Control System or IoT assets…
A solution to this problem would open a myriad possibilites.
The existing solutions
As it is a widespread known limitation in the community, people tried to solve the problem.
They conceived solutions that would fit their need, considering a set of functionalities and requirements, then built, released and deployed them successfully.
Some of them are famous:
CTFd whale is a CTFd plugin able to spin up Docker containers on demand.
CTFd owl is an alternative to CTFd whale, less famous.
KubeCTF is another CTFd plugin made to spin up Kubernetes environments.
Klodd is a rCTF service also made to spin up Kubernetes environments.
Nevertheless, they partially solved the root problem: those solutions solved the problem in a context (Docker, Kubernetes), with a Domain Specific Language (DSL) that does not guarantee non-vendor-lock-in nor ease use and testing, and lack functionalities such as Hot Update.
An ideal solution to this problem require:
the use of a programmatic language, not a DSL (non-vendor-lock-in and functionalities)
the capacity to deploy an instance without the solution itself (non-vendor-lock-in)
the capacity to use largely-adopted technologies (e.g. Terraform, Ansible, etc., for functionalities)
the genericity of its approach to avoid re-implementing the solution for every service provider (functionalities)
There were no existing solutions that fits those requirements… Until now.
Grey litterature survey
Follows an exhaustive grey litterature survey on the solutions made to solve the Challenge on Demand problem.
To enhance this one, please open an issue or a pull request, we would be glad to improve it !
¹ not considered scalable as it reuses a Docker socket thus require a whole VM. As such a VM is not scaled automatically (despite being technically feasible), the property aligns with the limitation.
Classification for Scalable:
✅ partially or completfully scalable. Classification does not goes further on criteria as the time to scale, autoscaling, load balancing, anticipated scaling, descaling, etc.
❌ only one instance is possible.
Litterature
More than a technical problem, the chall-manager also provides a solution to a scientific problem. In previous approaches for cybersecurity competitions, many referred to an hypothetic generic approach to the Challenge on Demand problem.
None of them introduced a solution or even a realistic approach, until ours.
In those approaches to Challenge on Demand, we find:
Even if there are some solutions developed to help the community deal with the Challenge on Demand problem, we can see many limitations: only Docker and Kubernetes are covered, and none is able to provide the required genericity to consider other providers, even custom ones.
A production-ready solution would enable the community to explore new kinds of challenges, both technical and scientific.
This is why we created chall-manager: provide a free, open-source, generic, non-vendor-lock-in and ready-for-production solution.
Feel free to build on top of it. Change the game.
What’s next ?
How we tackled down the complexity of building this system, starting from the architecture.
4.3 - Genericity
What is the layer of genericity ?
While trying to find a generic approach to deploy any infrastructure with a non-vendor-lock-in API, we looked at existing approaches. None of them proposed such an API, so we had to pave the way to a new future. But we did not know how to do it.
One day, after deploying infrastructures with Victor, we realised it was the solution. Indeed, Victor is able to deploy any Pulumi stack. This imply that the solution was already before our eyes: a Pulumi stack.
This consist the genericity layer, as easy as this.
Pulumi as the solution
To go from theory to practice, we had to make choices.
One of the problem with a large genericity is it being… large, actually.
If you consider all ecosystems covered by Pulumi, to cover them you’ll require all runtimes installed on the host machine.
For instance, the Pulumi Docker image is around 1.5 GB. This imply that a generic solution covering all ecosystems would be around 2 GB of memory.
Moreover, the enhancements you can propose in a language would have to be re-implemented similarly in every language, or transpiled. As transpilation is a heavy task, either manual or automatic but with a high error rate, it is not suitable for production.
Our choice was to focus on one language first (Golang), and later permit transpilation in other languages if technically automatable with a high success rate.
With this choice, we would only have to deal with the Pulumi Go Docker image, around 200 MB (a 7.5 reduction factor). It could be even more reduced using minified images, using the Slim Toolkit or Chainguard Apko.
From the idea to an actual tool
With those ideas in mind, we had to transition from TRLs by implementing it in a tool.
This tool could provide a service, thus the architecture was though as a Micro Service.
Doing so enable other Micro Services or CTF platforms to be developed and reuse the capabilities of chall-manager. We can then imagine plenty other challenges kind that would require Challenge on Demand:
All architecture documents, from the API to the Kubernetes deployment.
In the process of architecting a microservice, a first thing is to design the API exposed to the other microservices.
Once this done, you implement it, write the underlying software that provides the service, and think of its deployment architecture to fulfill the goals.
API
We decided to avoid API conception issues by using a Model Based Systems Engineering method, to focus on the service to provide. This imply less maintenance, an improved quality and stability.
This API revolve around a simplistic class diagram as follows.
the ChallengeStore to handle the challenges configurations
the InstanceManager to be the carrier of challenge instances on demand
Then, we described their objects and methods in protobuf, and using buf we generated the Golang code for those services. The gRPC API would then be usable by any service that would want to make use of the service.
Additionally, for documentation and ease of integration, we wanted a REST JSON API: through a gateway and a swagger, that was performed still in a code-generation approach.
Software
Based on the generated code, we had to implement the functionalities to fulfill our goals.
Functionalities and interactions of the chall-manager services, from a software point of view.
Nothing very special here, it was basically features implementation. This was made possible thanks to the Pulumi API that can be manipulated directly as a Go module with the auto package.
Notice we decided to avoid depending on a file-database such as an S3-compatible (AWS S3 or MinIO) as those services may not be compatible either to offline contexts or business contexts (due to the MinIO license being GNU AGPL-v3.0).
Nevertheless, we required a solution for distributed locking systems that would not fit into chall-manager. For this, we choosed etcd. File storage replication would be handled by another solution like Longhorn or Ceph. This is further detailed in High-Availability.
In our design, we deploy an etcd instance rather than using the Kubernetes already existing one. By doing so, we avoid deep integration of our proposal into the cluster which enables multiple instances to run in parallel inside an already existing cluster. Additionnaly, it avoids innapropriate service intimacy and shared persistence issues described as good development practices in Micro Services architectures by Taibi et al. (2020) and Bogard (2017).
Deployment
Then, multiple deployment targets could be discussed. As we always think of online, offline and on-premise contexts, we wanted to be able to deploy on a non-vendor-specific hypervisor everyone would be free to use. We choosed Kubernetes.
To lift the requirements and goals of the software, we had to deploy an etcd cluster, a deployment for chall-manager and a cronjob for the janitor.
The Kubernetes deployment of a chall-manager.
One opportunity of this approach is, as chall-manager is as close as possible to the Kubernetes provider (intra-cluster), it will be easily feasible to manage resources in it. Using this, ChallMaker and Ops could deploy instances on Demand with a minimal effort.
This is the reason why we recommend an alternative deployment in the Ops guides, to be able to deploy challenges in the same Kubernetes cluster.
Exposed vs. Scenario
Finally, another aspect of deployment is the exposed and scenario APIs.
The exposed one has been previously described, while the scenario one applies on scenarios once executed by the InstanceManager.
In the next section, you will understand how data consistency is performed while maintaining High Availability.
4.5 - High Availability
How we balanced Availability and Consistency for acceptable performances.
When designing an highly available application, the Availability and Consistency are often deffered to the database layer.
This database explains its tradeoff(s) according to the CAP theorem.
Nevertheless, chall-manager does not use a database for simplicity of use.
First of all, some definitions:
Availability is the characteristic of an application to be reachable to the final user of services.
High Availability contains Availability, with minimal interruptions of services and response times as low as possible.
To perform High Availability, you can use update strategies such as a Rolling Update with a maximum unavailability rate, replicate instances, etc.
But it depends on a property: the application must be scalable (many instances in parallel should not overlap in their workloads if not designed so), have availability and consistency mecanisms integrated.
One question then arise: how do we assure consistency with a maximal availability ?
Fallback
As the chall-manager should scale, the locking mecanism must be distributed. In case of a network failure, it imply that whatever the final decision, the implementation should provide a recovery mecanism of the locks.
Transactions
A first reflex would be to think of transactions. They guarantee data consistency, so would be good candidates.
Nevertheless, as we are not using a database that implements it, we would have to design and implement those ourselves.
Such an implementation is costfull and should only happen when reusability is a key aspect. As it is not the case here (specific to chall-manager), it was a counter-argument.
Mutex
Another reflex would be to think of (distributed) mutexes.
Through a mutual exclusion, we would be sure to guarantee data consistency, but nearly no availability.
Indeed, a single mutex would lock out all incoming requests until the operation is completly performed. Even if it would be easy to implement, it does not match our requirements.
Such implementation would look like the following.
We need something finer than (distributed) mutex: if a challenge A is under a CRUD operation, we don’t need challenge B to not be able to handle another CRUD operation !
We can imagine one (distributed) mutex per challenge such that they won’t stuck one another.
Ok, that’s fine… But what about instances ?
The same problem arise, the same solution: we can construct a chain of mutexes such that to perform a CRUD operation on an Instance, we lock the Challenge first, then the Instance, unlock the Challenge, execute the operation, and unlock the Instance. An API call from an upstream source or service is represented with this strategy as follows.
One last thing, what if we want to query all challenges information (to build a dashboard, janitor outdated instances, …) ?
We would need a “Stop The World"-like mutex from which every challenge mutex would require context-relock before operation. To differenciate this from the Garbage Collector ideas, we call this a “Top-of-the-World” aka TOTW.
That would guarantee consistency of the data while having availability on the API resources.
Nevertheless, this availability is not high availability: we could enhance further.
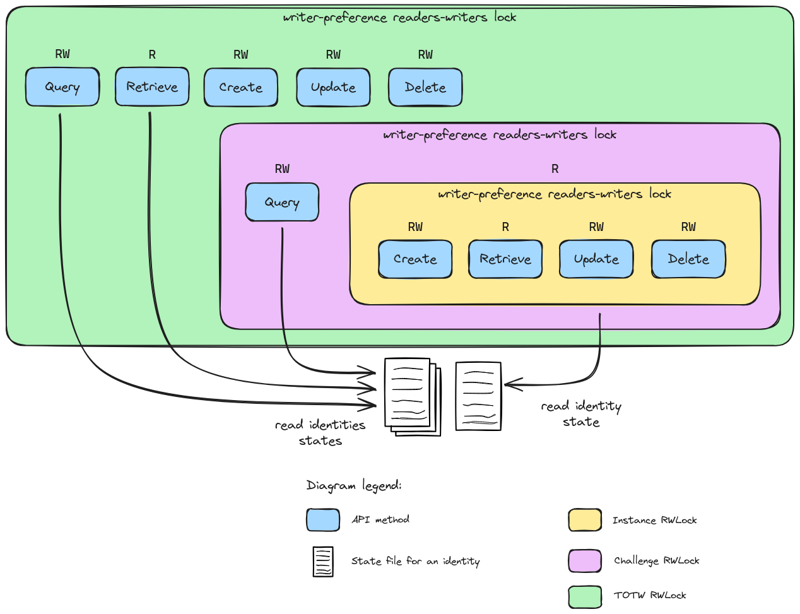
Writer-Preference Reader-Writer Distributed Lock
All CRUD operations are not equal, and can be split in two groups:
reading (Query, Read)
writing (Create, Update, Delete).
The reading operations does not affect the state of an object, while writing ones does.
Moreover, in the case of chall-manager, reading operations are nearly instantaneous and writing ones are at least 10-seconds long.
How to deal with those unbalanced operations ?
As soon as discussions on OS began, researchers worked on the similar question and found solutions. They called this one the “reader-writer problem”.
In our specific case, we want writer-preference as they would largely affect the state of the resources.
Using the Courtois et al. (1971) second problem solution for writer-preference reader-writer solution, we would need 5 locks and 2 counters.
For the technical implementation, we have multiple solutions: etcd, redis or valkey.
We decided to choose etcd because it was already used by Kubernetes, and the etcd client v3 already implement mutex and counters.
The triple chain of writer-preference reader-writer distributed locks.
With this approach, we could ensure data consistency throughout all replicas of chall-manager, and high-availability.
In our case, we are not looking for eventual consistency, but strict consistency. Moreover, using CRDT is costfull in development, integration and operation, so if avoidable they should be. CRDT are not the best tool to use here.
What’s next ?
Based on the guarantee of consistency and high availability, inform you on the other major problem: Hot Update.
4.6 - Hot Update
How do we handle the update of an infrastructure once it runs ?
When a challenge is affected by a bug leading to the impossibility of solving it, or if an unexpected solve is found, you will most probably want it fixed for fairness.
If this happens on challenge with low requirements, you will fix the description, files, hints, etc.
But what about challenges that require infrastructures ? You may fix the scenario, but it won’t fix the already-existing instances.
If no instance has been deployed, it is fine: fixing the scenario is sufficient. Once instances has been deployed, we require a mecanism to perform this update automatically.
A reflex when dealing with a question of updates and deliveries is to refer to The Update Framework.
With the embodiement of its principles, we wanted to provide macro models for hot update mecanisms.
To do this, we listed a bunch of deployment strategies, analysed their inner concepts and group them on this.
Precise model
Applicable
Macro model
Blue-Green deployment
✅
Blue-Green
Canary deployment
✅
Rolling deployment
✅
A/B testing
✅
Shadow deployment
✅
Red-Black deployment
✅
Highlander deployment
✅
Recreate
Recreate deployment
✅
Update-in-place deployment
✅
Update-in-place
Immutable infrastructure
❌
Feature toggles
❌
Dark launches
❌
Ramped deployment
❌
Serverless deployment
❌
Multi-cloud deployment
❌
Strategies were classified not applicable when they did not include update mecanisms.
With the 3 macro models, we define 3 hot update strategies.
Blue-Green
The blue-green update strategy starts a new instance with the new scenario, and once it is done shuts down the old one.
It requires both instances in parallel, thus is a resources-consuming update strategy. Nevertheless, it reduces services interruptions to low or none.
To the extreme, the infrastructure should be able to handle two times the instances load.
sequenceDiagram
Upstream ->>+ API: Request
API ->>+ New Instance: Start instance
New Instance ->>- API: Instance up & running
API ->>+ Old Instance: Stop instance
Old Instance ->>- API: Done
API ->>- Upstream: Respond new instance info
Recreate
The recreate update strategy shuts down the old one, then starts a new instance with the new scenario.
It is a resources-saving update strategy, but imply services interruptions enough time to stop the old instance and starts a new one.
To the extreme, it does not require additional resources more than one time the instance load.
sequenceDiagram
Upstream ->>+ API: Request
API ->>+ Old Instance: Stop instance
Old Instance ->>- API: Done
API ->>+ New Instance: Start instance
New Instance ->>- API: Instance up & running
API ->>- Upstream: Respond refreshed instance info
Update-in-place
The update-in-place update strategy loads the new scenario and update resources in live.
It is a resource-saving update strategy, that imply low to none services interruptions, but require robustness in the update mecanisms. If the update mecanisms are not robust, we do not recommend this one as it could soft-lock resources in the providers.
To the extreme, it does not require additional resources more than one time the instance load.
sequenceDiagram
Upstream ->>+ API: Request
API ->>+ Instance: Update instance
Instance ->>- API: Refreshed instance
API ->>- Upstream: Respond refreshed instance info
Overall
Update Strategy
Require Robustness¹
Time efficiency
Cost efficiency
Availability
TL;DR;
Update in place
✅
✅
✅
✅
Efficient in time & cost ; require high maturity
Blue-Green
❌
✅
❌
✅
Efficient in time ; costfull
Recreate
❌
❌
✅
❌
Efficient in cost ; time consuming
¹ Robustness of both the provider and resources updates.
What’s next ?
How did we incorporate security in such a powerfull service ?
Find answers in Security.
4.7 - Security
Learn how we designed security in a “RCE-as-a-Service” system, and how we used its features for security purposes.
The problem with the genericity of chall-manager resides in its capacity to execute any Golang code as long as it fits in a Pulumi stack i.e. anything. For this reason, there are multiple concerns to address when using the chall-manager.
Nevertheless, it also provides actionable responses to security concerns, such as shareflag and bias.
Authentication & Authorization
A question regarding such a security concern of an “RCE-as-a-Service” system is to throw authentication and authorization at it. Technically, it could fit and get justified.
Nevertheless, we think that, first of all, chall-manager replicas should not be exposed to end users and untrusted services thus Ops should put mTLS in place between trusted services and restraint communications to the bare minimum, and secondly, the Separation of Concerns Principle imply authentication and authorization are another goal thus should be achieved by another service.
Finally, authentication and authorization may but justifiable if Chall-Manager was operated as a Service. As this would not be the case with a Community Edition, we consider it out of scope.
Kubernetes
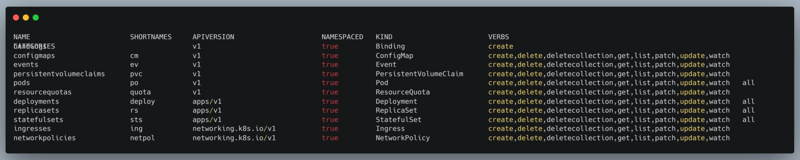
If deployed as part of a Kubernetes cluster, with a ServiceAccount and a specific namespace to deploy instances, the chall-manager is able to mutate the architecture on the fly. To minimize the effect of such mutations, we recommend you provide this ServiceAccount a Role with a limited set of verbs on api groups. Those resources should only be namespaced.
To build this Role for your needs, you can use the command kubectl api-resources –-namespaced=true –o wide to visualize a cluster resources and applicable verbs.
An extract of a the resources of a Kubernetes cluster and their applicable verbs.
One of the actionable response provided by the chall-manager is through an anti-shareflag mecanism.
Each instance deployed by the chall-manager can return in its scenario a specific flag. This flag will then be used by the upstream CTF platform to ensure the source -and only it- found the solution.
Moreover, each instance-specific flag could be derived from an original constant one using the flag variation engine.
ChallOps bias
As each instance is an infrastructure in itself, variations could bias them: lighter network policies, easier brute force, etc.
A scenario is not biased by essence.
If we make a risk analysis on the chall-manager capabilities and possibilities for an event, we have to consider a biased ChallMaker or Ops that produces uneven-balanced scenarios.
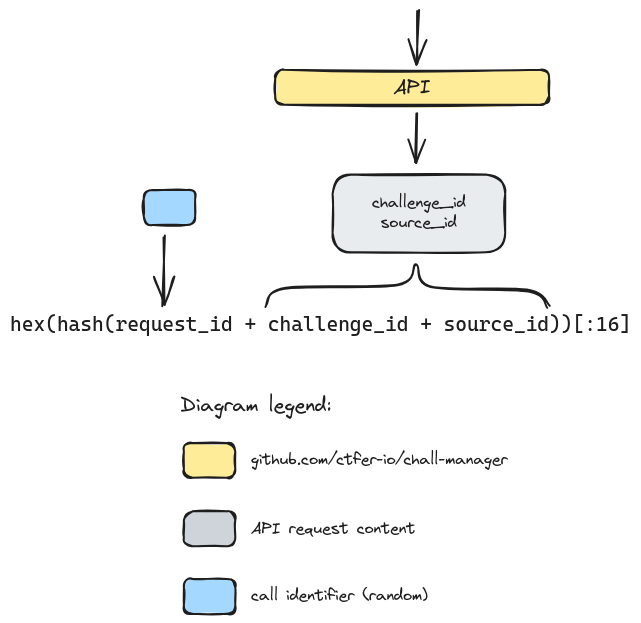
For this reason, the chall-manager API does not expose the source identifier of the request to the scenario code, but an identity. This is declined as follows. It strictly identifies an infrastructure identifier, the challenge the instance was requested from, and the source identifier for this instance.
A visualization of how views are split apart to avoid the ChallOps bias.
Notice the identity is limited to 16 hexadecimals, making it compatible to multiple uses like a DNS name or a PRNG seed. This increases the possibilites of collisions, but can still cover \(16^{16} = 18.446.744.073.709.551.616\) combinations, trusted sufficient for a CTF (\(f(x,y) = x \times y - 16^{16}\), find roots: \(x \times y=16^{16} \Leftrightarrow y=\frac{16^{16}}{x}\) so roots are given by the couple \((x, \frac{16^{16}}{x})\) with \(x\) the number of challenges. With largely enough challenges e.g. 200, there is still place for \(\frac{16^{16}}{200} \simeq 9.2 \times 10^{16}\) instances each).
Find how we handle fairness in the use of infrastructure resources with expirations.
Context
During the CTF, we don’t want players to be capable of manipulating the infrastructure at their will: starting instances are costful, require computational capabilities, etc.
It is mandatory to control this while providing the players the power to manipulate their instances at their own will.
For this reason, one goal of the chall-manager is to provide ephemeral (or not) scenarios. Ephemeral imply lifetimes, expirations and deletions.
To implement this, for each Challenge the ChallMaker and Ops can set a timeout in seconds after which the Instance will be deleted once up & running, or an until date after which the instance will be deleted whatever the timeout. When an Instance is deployed, its start date is saved, and every update is stored for traceability. A participant (or a dependent service) can then renew an instance on demand for additional time, as long as it is under the until date of the challenge. This is based on a hypothesis that a challenge should be solved after \(n\) minutes.
Note
The timeout should be evaluated based on expert’s point of view regarding the complexity of the conceived challenge, with a consideration of the participant skill sets (an expert can be expected to solve an introduction challenge in seconds, while a beginer can take several minutes).
There is no “rule of the thumb”, but we recommend double-testing the challenge by both a domain-expert for technical difficulty and another ChallMaker unrelated to this domain.
Deleting instances when outdated then becomes a new goal of the system, thus we cannot extend the chall-manager as it would be a rupture of the Separation of Concerns Principle: it is the goal of another service, chall-manager-janitor. This is also justified by the frequency model applied to the janitor, which is unrelated to the chall-manager service itself.
With such approach, other players could use the resources. Nevertheless, it requires a mecanism to wipe out infrastructure resources after a given time.
Some tools exist to do so.
Despite tools exist, they are context-specifics thus are limited: each one has its own mecanism and only 1 environment is considered.
As of genericity, we want a generic approach able to handle all ecosystems without the need for specific implementations.
For instance, if ChallMakers decide to cover a unique, private and offline ecosystem, how could they do ?
That is why the janitor must have the same level of genericity as chall-manager itself.
Despite it is not optimal for specifics providers, we except this genericity to be a better tradeoff than covering a limited set of technologies. This modular approach enable covering new providers (vendor-specifics, public or private) without involving CTFer.io in the loop.
How it works
By using the chall-manager API, the janitor looks up at expiration dates.
Once an instance is expired, it simply deletes it.
Using a cron, the janitor could then monitor the instances frequently.
flowchart LR
subgraph Chall-Manager
CM[Chall-Manager]
Etcd
CM --> Etcd
end
CMJ[Chall-Manager-Janitor]
CMJ -->|gRPC| CM
If two janitors triggers in parallel, the API will maintain consistency. Errors code are to expect, but no data inconsistency.
As it does not plugs into a specific provider mecanism nor requirement, it guarantees platform agnosticity. Whatever the scenario, the chall-manager-janitor will be able to handle it.
Follows the algorithm used to determine the instance until date based on a challenge configuration for both until and timeout.
Renewing an instance re-execute this to ensure consistency with the challenge configuration.
Based on the instance until date, the janitor will determine whether to delete it or not (\(instance.until > now() \Rightarrow delete(instance)\)).
How to reach tremendous performances by pre-provisionning instances.
Warning
Ahead of any explanation, it must be understood that the pooler, despite being a major feature for quality, is to deeply consider regarding infrastructure overhead between Ops and ChallMakers. It may increase your infrastructure load until DoS or largely raise the bill for hosting instances without them being used.
It is nonetheless vital whenever giving players the best experience is part of your project.
Context
Due to the genericity of the design the abstraction layer imply generic operations. For instance, loading the Pulumi stack might take seconds, and by summing up all of these operations, it creates an uncompressible time to handle an API request.
Then, deploying the resources can take several seconds up to several minutes depending on the scenario. Finally, writing it all down on the filesystem and serving the result adds more time to the response.
Through this process, there are uncompressible times, with mostly the only variation depending on the scenario. Increasing the throughout of Chall-Manager can then focus on 3 things :
Filesystem operations, but have a small impact on the overall plus would be dangerous to do it ourself rather than depending on Go’s team work ;
Improving locking operations, reducing the consistency of data thus be dangerous with unpredictable errors ;
Improve Pulumi’s code to go faster, but with such a complex codebase might end up being a highly complex unmaintainable codebases.
Based on this, we consider there is no room for improving the process, in our scope.
An approach that would work would be to pre-provision instances for your players such that everyone as its own whenever they want to.
This would work under the condition that you know how many players you have, but would also decrease your infrastructure capability as you would require a lot of probably unused resources (e.g. CPUs) that would better fit elsewhere.
What we can change, in our scope, are the workflows.
Indeed, what if indeed of deploying instances on demand, we deploy them ahead of requesting them, by creating a pool of already deployed instance ?
In this model, instance can either be claimed by a source or pre-provisionned into a pool (not both).
To implement this, we create a new “Service” called the Pooler. Each challenge has its own, disabled by default (min=0, max=0).
A pooler is defined per attributes:
min (default=0) which defines how many instances should be pre-deployed ;
max (default=0) which defines a threshold after which it stops pre-provisionning them.
Setting a max != 0 but min = 0 has no impact on the pooler i.e. won’t pre-deploy any instance.
Requesting an instance
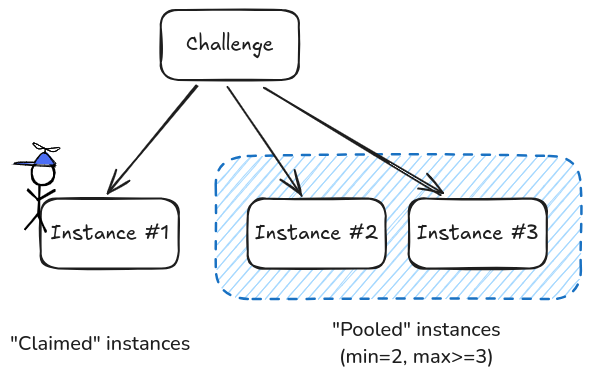
Running the pooler end up separating running instances in two groups:
the claimed instances, which are instances assigned to sources ;
the pooled instances, not claimed yet but available for so.
Visualization of a pooler turned on, with claimed and pooled instances.
Configuration is `min=2` and an unknown `max` that must be `>=3` in this case.
When a source issue the API call to create an instance (ist) of a challenge (ch), the following workflow occurs.
flowchart LR
A["Request _ist_"] --> B
B("Get _ch_") --> C
C{"#_ists_pool_ > 0"}
C -->|No| D("Create new _ist_")
D --> E[Return _ist_]
C -->|Yes| F(Claim _ist_)
F --> I{"Has additional ?"}
I -->|No| E
I -->|Yes| J("Update stack")
J -->E
F -->|async| G{"#_ists_ < max"}
G -->|Yes| H("Create new _ist_ in pool")
The API request to create the challenge spawns goroutines that will each be in charge of adding an instance in the pool. This is performed asynchronously such that it does not hold a long-living request, making automation around Chall-Manager easier.
The same pattern is triggered when an instance is picked from the pool and must be restored to its original capacity.
Nevertheless, it implies that if an instance is requested before there is any in the pool, it will deploy a brand new one rather than picking one in the pool.
Note
Tests showed that from even a small scenario that does not deploy resources, claiming an instance was around 640 µs, while deploying a brand new one was between 2 to 3 seconds.
On a big scenario (e.g. a VM-based lab) that could take minutes to complete, the same performances are to expect, i.e. from minutes to less than a millisecond.
Resizing
When a challenge is updated, if there is any change to the pooler configuration, the planned pool size is computed. Then the difference between the state and the plan is performed. If there are too many pooled instances running, the difference is deleted. Similarly, if there ain’t enough, the difference is created. All untouched instances are updated as for the claimed instances.
The algorithm for this won’t be detailed but lays here.
Impact
To illustrate the impact problem of the pooler, let’s consider an instance which costs 2 vCPUs, 8 Go of RAM and 20 Go of disk space. In this factice infrastructure, the limitating component is the CPU.
By itself, the infrastructure’s capabilities might be sufficient to handle enough instances for all players, but with adjacent challenges and the backbone it becomes unviable. That way, you can’t consider pre-provisionning all instances, and have not enough data to pre-provision part of them. A deployment takes 5 minutes so leads to an unacceptable quality for your players: you must use the pooler.
Using the pooler is a balance between time and experience from the Player and ChallMaker perspective, but a balance between performances and costs for the Ops and Admins perspective. When we discuss costs we consider the use of physical resources (e.g. CPU, RAM, disk), and the corresponding financial costs from a host/cloud service provider. This double balance between quality and costs leads to an undecidable problem.
To help in the decision, we recommend you consider the advantage of having instances in the pool depending mostly on the cost of one instance.
Under high load, there might be instances in the pool where the global knowledge should recommend not having some. This issue can simply be dealt with by updating the challenge with no change (it triggers the delta algorithm). Given these conditions, the worst case (infrastructure impact) is given by the sum of all individuals costs \( c_i \) of every possible instances in \( \mathscr{I} \): \( cost = \sum_{i = 0 }^{\left| \mathscr{I} \right|} c_i \).
By considering the individual cost \( c_i \) even for all instances as \( c \), it can be simplified as \( cost = c \times \left| \mathscr{P} \right| = c \times \big(\left| pool \right| + \left| sources \right| \big) \), with \( \left| pool \right| \) the minimum pool size (min attribute) and \( \left| sources \right| \) the total number of expected players in the worst case.
In prose, the worst case cost on infrastructure is given by the total number of players and the minimum pool size multiplied by the mean cost of a single instance. This last can be determined by the limitating characteristic of the hosting infrastructure.
Use cases
The following are fictive yet realistic use cases of the pooler.
Limited resources
Let’s say we have a challenge that requires multiple VMs in network. We refer to such environment as a “lab”.
This lab takes too long to deploy, thus would end up frustrating players, degrading the quality of the event.
For this reason, you decide to use the pooler such that there is always some (e.g. 3) labs available for players to instantaneously pick from.
Nevertheless, you have 30 teams thus won’t require much more instances in the worst case. Moreover, with a lot of challenges, you only expect 10 teams at most in parallel.
You set up the pooler as min=3 and max=10.
This means you want to have 3 labs deployed in parallel, ready to be picked by your players, but won’t require more than 10 (the worst case you consider) after which the pool stops working. Notice it does not block more instances to be deployed if your maths ends up inaccurate, but these won’t be picked up quickly as they need to be freshly deployed.
Using these settings, players of your event will have a good feeling about the quality of your event, with time to focus on the challenge rather than waiting for the infrastructure to be ready.
Online platform
Let’s say you are using Chall-Manager as a backend service for an online cybersecurity training platform. You want to always have available instances for people to train actively rather than clicking and having to wait several minutes -especially your VIPs-.
Based on the usage statistics of previous similar challenges, the communication you put in place around it, you expect an instance to be requested every 10 minutes in average for the upcoming days, with a spike of 1 every minute for the first day. Experimentally, you measure an instance takes (for instance) 6 minutes to deploy.
You want to always have 20 instances such that there is also room for people who would like to retry the box from scratch (either they broke it, they want to try an automated solution, speedrun the box, test a write-up…).
You set up the pooler as min=20, and no max.
After the first day, you reconsider these settings and redefine min=4.
Finally, after a while you turn the pooler into a minimal level of availability, i.e. min=2 and max=4.
This procedure makes your challenge able to handle the load of incoming requests without knowing how many people are going to try it.
However, these settings expects you have plenty infrastructure capabilities, enough to consider that you won’t need a maximum at first. In that case, please actively monitor your resources to ensure there is no abuse, and if so, to take decisions on blocking people and/or set an arbitrary max value ahead of the plan.
4.10 - Software Development Kit
Learn how we designed a SDK to ease the use of chall-manager for non-DevOps people.
A first comment on chall-manager was that it required ChallMaker and Ops to be DevOps. Indeed, if we expect people to be providers’ experts to deploy a challenge, when there expertise is on a cybersecurity aspect… well, it is incoherent.
To avoid this, we took a few steps back and asked ourselves: for a beginner, what are the deployment practices that could arise form the use of chall-manager ?
A naive approach was to consider the deployment of a single Docker container in a Cloud provider (Kubernetes, GCP, AWS, etc.).
For this reason, we implemented the minimal requirements to effectively deploy a Docker container in a Kubernetes cluster, exposed through an Ingress or a NodePort. The results were hundreds-line-long, so confirmed we cannot expect non-professionnals to do it.
Based on this experiment, we decided to reuse this Pulumi scenario to build a Software Development Kit to empower the ChallMaker. The references architectures contained in the SDK are available here.
The rule of thumb with them is to infer the most possible things, to have a mimimum configuration for the end user.
Other features are available in the SDK.
Flag variation engine
Commonly, each challenge has its own flag. This suffers a big limitation that we can come up to: as each instance is specific to a source, we can define the flag on the fly. But this flag must not be shared with other players or it will enable shareflag.
For this reason, we provide the ability to mutate a string (expected to be the flag): for each character, if there is a variant in the ASCII-extended charset, select one of them randomly and based on the identity.
Variation rules
The variation rules follows, and if a character is not part of it, it is not mutated (each variant has its mutations evenly distributed):
o, O, 0, ¤, °, º, Ò, Ó, Ô, Õ, Ö, Ø, ø, ò, ó, ô, õ, ö, ð
p, P
q, Q
r, R, ®
s, S, 5, $, š, Š, §
t, T, 7, †
u, U, µ, Ù, Ú, Û, Ü, ù, ú, û, ü
v, V
w, W
x, X, ×
y, Y, Ÿ, ¥, Ý, ý, ÿ
z, Z, ž, Ž
, -, _, ~
Tips & Tricks
If you want to use a decorator (e.g. BREFCTF{...}), do not put it in the flag to variate. More info here.
Limitations
We are aware that this proposition does not solve all issues: if people share their write-up, they will be able to flag.
This limitation is considered out of our scope, as we don’t think the Challenge on Demand solution fits this use case.
Nevertheless, our differentiation strategy can be the basis of a proper solution to the APG-problem (Automatic Program Generation): we are able to write one scenario that will differentiate the instances per source. This could fit the input of an APG-solution.
Moreover, it considers a precise scenario of advanced malicious collaborative sources, where shareflag consider malicious collaborative sources only (more “accessible” by definition).
Additional configuration
When creating your first scenarios, you have a high coupling between your idea and how it is deployed. But as time goes, you create helper functions that abstracts the complexity and does most of the job for you (e.g. the kubernetes.ExposedMonopod).
Despite those improvements, for every challenge that are deployed the same way (for instance, on the NoBrackets 2024, more than 90% of the challenges were deployed by the same scenario with a modified configuration), you have to redo the job multiple times: duplicate, reconfigure, compile, archive, test, destroy, push, …
Furthermore, if you want to provide fine-grained data to the scenario, you could not. For instance, to edit firewall rules to access a bunch of VMs or a CPS, you may want to provide the scenario the requester IP address. This require on-the-fly configuration to be provided to the scenario when the Instance is created.
To solve both problems, we introduced the additional configurationkey=value pairs. Both the Challenge and the Instance can provide their configuration pairs to the scenario. They are merged from the Instance’s pairs over the Challenge’s pairs thus enable key=value pair overwrite if necessary, e.g. to overload a default value.
This open the possibility of creating a small set of scenarios that will be reconfigured on the fly by the challenges (e.g. the previous NoBrackets 2024 example could have run over 2 scenarios for 14 challenges).
What’s next ?
The final step from there is to ensure the quality of our work, with testing.
4.11 - Testing
Building something cool is a thing, assuring its quality is another. Learn how we dealt with this specific service Integration, Verification and Validation, especially through Romeo.
Generalities
In the goal of asserting the quality of a software, testing becomes a powerful tool: it provides trust in a codebase. But testing, in itself, is a whole domain of IT.
Some common requirements are:
having those tests written with a programmation language (most often the same one as the software, enable technical skills sharing among Software Engineers)
documented (the high-level strategy should be auditable to quickly assess quality practices)
reproducible (could be run in two distinct environments and produce the same results)
explainable (each test case sould document its goal(s))
systematically run, or if not possible, as frequent as possible (detect regressions as soon as possible)
To fulfill those requirements, the strategy can contain many phases which each focused on a specific aspect or condition of the software under tests.
In the following, we provide the high-level testing strategy of the chall-manager Micro Service.
Software Engineers are invited to read it as such strategy is rare: we challenged the practices to push them beyond what the community does, with Romeo.
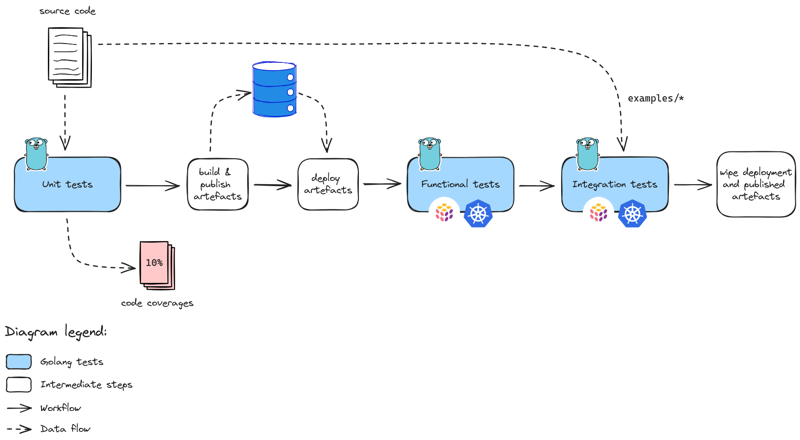
Testing strategy
The testing strategy contains multiple phases:
unit tests to ensure core functions behave as expected ; those does not depend on network, os, files, etc. out thus the code and only it.
functional tests to ensure the system behaves as expected ; those require the system to run hence a place to do so.
integration tests to ensure the system is integrated properly given a set of targets ; those require whether the production environment or a clone of it.
The chall-manager testing strategy.
Additional Quality Assurance steps could be found, like Stress Tests to assess Service Level Objectives under high-load conditions.
In the case of chall-manager, we write both the code and tests in Golang. To deploy infrastructures for tests, we use the Pulumi automation API and on-premise Kubernetes cluster (built using Lab and L3).
Unit tests
The unit tests revolve around the code and are isolated from anything else: no network, no files, no port listening, other tests, etc.
This provides them the capacity to get run on every machine and always produce the same results: idempotence.
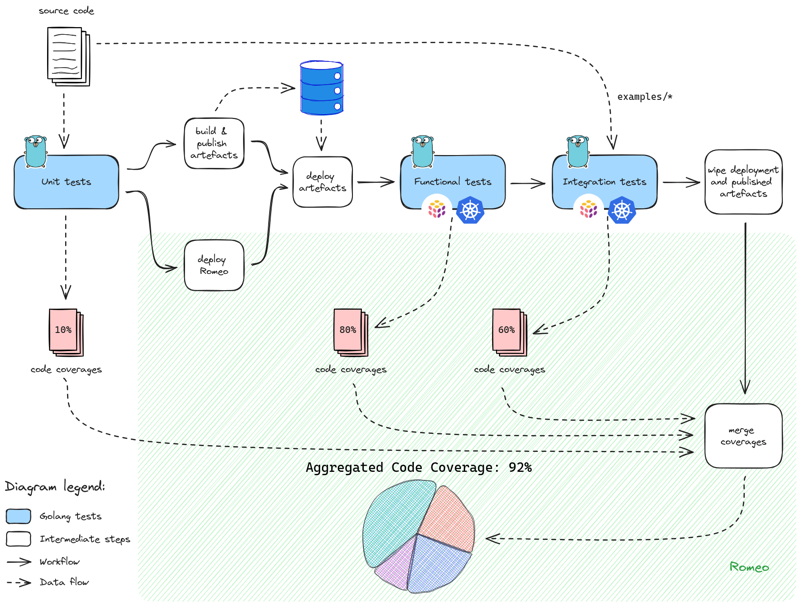
As chall-manager is mostly a wrapper around the Pulumi automation API to deploy scenarios, it could not be much tested using this step. Code coverage could barely reach \(10\%\) thus confidence is not sufficient.
Convention is to prefix these tests Test_U_ hence could be run using go test ./... -run=^Test_U_ -v.
They most often have the same structure, based on Table-Driven Testing (TDT). Some diverge to fit specific needs (e.g. no regression on an issue related to a state machine).
packagexxx_testimport("testing""github.com/stretchr/testify/assert")funcTest_U_XXX(t*testing.T){t.Parallel()vartests=map[string]struct{// ... inputs, expected outputs
}{// ... test cases each named uniquely
// ... fuzz crashers if applicable, named "Fuzz_<id>" and a description of why it crashed
}fortestname,tt:=rangetests{t.Run(testname,func(t*testing.T){assert:=assert.New(t)// ... the test body
// ... assert expected outputs
})}}
Functional tests
The functional tests revolve around the system during execution, and tests behaviors of services (e.g. state machines).
Those should be reproducible, but some unexpected behaviors could arise: network interruptions, no disk available, etc. but should not be considered as the first source of a failing test (the underlying infrastructure is most often large enough to run the test, without interruption).
Convention is to prefix these tests Test_F_ hence could be run using go test ./... -run=^Test_F_ -v.
They require a Docker image (build artifact) to be built and pushed to a registry. For Monitoring purposes, the chall-manager binary is built with the -cover flag to instrument the Go binary such that it exports its coverage data to filesystem.
As they require a Kubernetes cluster to run, you must define the environment variable K8S_BASE with the DNS base URL to reach this cluster.
Cluster should fit the requirements for deployment.
Their structure depends on what needs to be tested, but follows TDT approach if applicable.
Deployment is performed using the Pulumi factory.
packagexxx_testimport("os""path""testing""github.com/stretchr/testify/assert")funcTest_F_XXX(t*testing.T){// ... a description of what is the goal of this test: inputs, outputs, behaviors
cwd,_:=os.Getwd()integration.ProgramTest(t,&integration.ProgramTestOptions{Quick:true,SkipRefresh:true,Dir:path.Join(cwd,".."),// target the "deploy" directory at the root of the repository
Config:map[string]string{// ... more configuration
},ExtraRuntimeValidation:func(t*testing.T,stackintegration.RuntimeValidationStackInfo){// If TDT, do it here
assert:=assert.New(t)// ... the test body
// ... assert expected outputs
},})}
Integration tests
The integration tests revolve around the use of the system in the production environment (or most often a clone of it, to ensure no service interruptions on the production in case of a sudden outage).
In the case of chall-manager, we ensure the examples can be launched by the chall-manager. This requires us the use of multiple providers, thus a specific configuration (to sum it up, more secrets than the functional tests).
Convention is to prefix these tests Test_I_ hence could be run using go test ./... -run=^Test_I_ -v.
They require a Docker image (build artifact) to be built and pushed to a registry. For Monitoring purposes, the chall-manager binary is built with the -cover flag to instrument the Go binary such that it exports its coverage data to filesystem.
As they require a Kubernetes cluster to run, you must define the environment variable K8S_BASE with the DNS base URL to reach this cluster.
Cluster should fit the requirements for deployment.
Their structure depends on what needs to be tested, but follows TDT approach if applicable.
Deployment is performed using the Pulumi factory.
packagexxx_testimport("os""path""testing""github.com/stretchr/testify/assert")funcTest_I_XXX(t*testing.T){// ... a description of what is the goal of this test: inputs, outputs, behaviors
cwd,_:=os.Getwd()integration.ProgramTest(t,&integration.ProgramTestOptions{Quick:true,SkipRefresh:true,Dir:path.Join(cwd,".."),// target the "deploy" directory at the root of the repository
Config:map[string]string{// ... configuration
},ExtraRuntimeValidation:func(t*testing.T,stackintegration.RuntimeValidationStackInfo){// If TDT, do it here
assert:=assert.New(t)// ... the test body
// ... assert expected outputs
},})}
Monitoring coverages
Beyond testing for Quality Assurance, we also want to monitor what portion of the code is actually tested.
This helps Software Development and Quality Assurance engineers to pilot where to focus the efforts, and in the case of chall-manager, what conditions where not covered at all during the whole process (e.g. an API method of a Service, or a common error).
By monitoring it and through public display, we challenge ourselves to improve to an acceptable level (e.g. \(\ge 85.00\%\)).
Disclaimer
Do not run after coverages: \(100\%\) code coverage imply no room for changes, and could be a burden to develop, run and maintain.
What you must cover are the major and minor functionalities, not all possible node in the Control Flow Graph. A good way to start this is by writing the tests by only looking at the models definition files (contracts, types, documentation).
When a Pull Request is opened (whether dependabot for automatic updates, a bot or an actual contributor), the tests are run thus helps us understand the internal changes. If the coverage decreases suddenly with the PR, reviewers would ask the PR author(s) to work on tests improvement.
It also makes sure that the contribution won’t have breaking changes, thus no regressions on the covered code.
For security reasons, the tests that require platform deployments require a first review by a maintainer.
To perform monitoring of those coverages, we integrate Romeo in the testing strategy as follows.
Coverages extract performed on the high-level testing strategy used for chall-manager. Values are fictive.
By combining multiple code coverages we build an aggregated code coverage higher than what standard Go tests could do.
5 - Tutorials
A set of tutorials to use the Chall-Manager.
5.1 - A complete example
Let’s go from a challenge idea to chall-manager deploying instances !
In the current documentation page, we will go through every step a ChallMaker will encounter, from the concept to players deploying instances in production.
flowchart LR
Concept --> Build
Build --> Scenario
Scenario --> Pack
Pack --> Deploy
subgraph Build
B1["Docker image"]
end
subgraph Scenario
S1["Pulumi.yaml"]
subgraph ExposedMonopod
S2["main"]
end
S1 -.-> S2
end
subgraph Pack
P1["scenario.zip"]
end
The concept
Imagine you are a ChallMaker who wants to challenge players on web application pentest.
The challenge is an application that require a licence to unlock functionalities, especially one that can read files vulnerable to local file inclusion. The initial access is due to an admin:admin account. The state of the application will be updated once the licence check is bypassed.
Its artistic direction is considered out of scope for now, but you’ll find this example all along our documentation !
flowchart LR
A["Web app access"]
A --> |"Initial access with admin:admin"| B
B["Administrator account"]
B --> |"License validation"| C
C["Unlock vulnerable feature"]
C --> |"Local File Inclusion"| D
D["Read flag"]
Obviously, you don’t want players to impact others during their journey: Challenge on Demand is a solution.
Build the challenge
Using your bests software engineering skills, you conceive the application in the language of your choice, with the framework you are used to.
You quickly test it, everthing behaves as expected, so you build a Write-Up for acceptance by reviewers.
This challenge is then packed into a Docker image: account/challenge:latest
We will then want to deploy this Docker image for every source that wants it.
Construct the scenario
To deploy this scenario, we don’t have big needs: one container, and a Kubernetes cluster.
We’ll use the Kubernetes ExposedMonopod to ease its deployment.
First of all, we create the Pulumi.yaml file to handle the scenario.
We write it to handle a pre-compiled binary of the scenario, for better performances.
Pulumi.yaml
name:stateful-webappdescription:The scenario to deploy the stateful web app challenge.runtime:name:gooptions:binary:./main
Create the Go module using go mod init example.
Then, we write the scenario file.
main.go
packagemainimport("github.com/ctfer-io/chall-manager/sdk""github.com/ctfer-io/chall-manager/sdk/kubernetes""github.com/pulumi/pulumi/sdk/v3/go/pulumi")funcmain(){sdk.Run(func(req*sdk.Request,resp*sdk.Response,opts...pulumi.ResourceOption)error{cm,err:=kubernetes.NewExposedMonopod(req.Ctx,"example",&kubernetes.ExposedMonopodArgs{Identity:pulumi.String(req.Config.Identity),// identity will be prepended to hostname
Hostname:pulumi.String("brefctf.ctfer.io"),// CTF hostname
Container:kubernetes.ContainerArgs{Image:pulumi.String("account/challenge:latest"),// challenge Docker image
Ports:kubernetes.PortBindingArray{kubernetes.PortBindingArgs{Port:pulumi.Int(8080),ExposeType:kubernetes.ExposeIngress,},},},IngressAnnotations:pulumi.ToStringMap(map[string]string{// annotations for the ingress to target the service
"traefik.ingress.kubernetes.io/router.entrypoints":"web, websecure",}),IngressNamespace:pulumi.String("networking"),// the namespace in which the ingress is deployed
IngressLabels:pulumi.ToStringMap(map[string]string{// the labels of the ingress pods
"app":"traefik",}),},opts...)iferr!=nil{returnerr}resp.ConnectionInfo=pulumi.Sprintf("curl -v https://%s",cm.URLs.MapIndex(pulumi.String("8080/TCP")))// a simple web server
returnnil})}
Download the required dependencies using go mod tidy.
To test it you can open a terminal and execute pulumi up. It requires your host machine to have a kubeconfig or a ServiceAccount token in its filesystem, i.e. you are able to execute commands like kubectl get pods -A.
Finally, compile using CGO_ENABLED=0 go build ./main main.go.
Send it to chall-manager
The challenge is ready to be deployed. To give those information to chall-manager, you have to build the scenario zip archive.
As the scenario has been compiled, we only have to archive the Pulumi.yaml and main files.
zip -r scenario.zip Pulumi.yaml main
Then, you have to create the challenge (e.g. some-challenge) in chall-manager. You can do it using the gRPC API or the HTTP gateway.
We’ll use chall-manager-cli to do so easily.
Now, chall-manager is able to deploy our challenge for players.
Deploy instances
To deploy instances, we’ll mock a player (e.g. mocking-bird) Challenge on Demand request using chall-manager-cli.
In reality, it would be to the CTF platform to handle the previous step and this one, but it is considered out of scope.
This will return us the connection information to our instance of the challenge.
6 - Security
Explanations on the Security problems that could arise from a chall-manager deployment.
RCE-as-a-Service
Through the whole documentation, we often refer to chall-manager as an RCE-as-a-Service platform. Indeed it executes scenarios on Demand, without authentication nor authorization.
For this reason, we recommend deployments to be deeply burried in the infrastructure, with firewall rules or network policies, encrypted tunnels between the dependent service(s), and anything else applicable.
Under no condition you should launch it exposed to participants and untrusted services.
If not, secrets could be exfiltrated, host platform could be compromised, etc.
Kubernetes
If you are not using the recommended architecture, please make sure to not deploy instances in the same namespace as the chall-manager instances are deployed into. Elseway, players may pivot through the service and use the API for malicious purposes.
Additionally, please make sure the ServiceAccount the chall-manager Pods use has only its required permissions, and if possible, only on namespaced resources. To build this, you can use kubectl api-resources –-namespaced=true –o wide.
Sharing is caring
As the chall-manager could become costful to deploy and maintain at scale, you may want to share the deployments between multiple plateforms.
Notice the Community Edition does not provide isolation capabilities, so secrets, files, etc. are shared along all scenarios.
7 - Glossary
The concepts used or introduced by the Chall-Manager.
Challenge on Demand
The capacity of a CTF platform to empower a source to deploy its own challenges autonomously.
Scenario
It is the refinement of an artistic direction for a CTF.
In the case of Chall-Manager, it could be compared as the recipe of deployment for a given challenge.
Technically, the scenario is a Pulumi entrypoint written in Go that conforms to the SDK.
When launched, it deploys the source’s infrastructure and return data such as the connection information or an instance-specific flag.
Source
Either a team or user at the origin of a request.
For abstraction purposes, we consider it being the same under the use of the “source” term.
Identity
An identity tie a challenge, a source and an instance request together. This last one is random (crypto) thus can’t be guessed.
It enable the chall-manager to strictly identify resources as part of separate instances running at the same spot, and provide the scenario a reproductible random seed in case of update (idempotence is not guaranteed through the challenge lifecycle).
Identity production process.
Instance
An instance is the product of a scenario, once launched with an identity.
Player
A player is a CTF participant who is going to manipulate instances of challenges throughout the lifetime of the event.
ChallMaker
The designer of the challenge, often with a security expert profile on the category contributed to.
This is an essential role for a CTF event, as without them, the CTF would simply not exist !
Notice it is the responsibility of the ChallMaker to make its challenge playable, not the Ops.
If you can’t make your challenge run into pre-prod/prod, you can’t blame the Ops.
They collaborate with plenty profiles:
other ChallMakers to debate its ideas and assess the difficulty.
Ops to make sure its challenges can reach production smoothly.
Admins to discuss the technical feasibility of its challenges, for instance if it requires FPGAs, online platforms as GCP or AWS, etc. or report on the status of the CTF.
an artistic direction, graphical designer, etc. to assist on the coherence of the challenge in the whole artistic process.
Ops
The Operator of the event who ensure the infrastructure is up and running, everything runs untroubled thus players can compete.
They do not need to be security experts, but might probably be due to the community a CTF brings.
They are the rulers of the infrastructure, its architecture and its incidents. ChallMakers have both fear and admiration on them, as they enable playing complex scenarios but are one click away of destructing everything.
They collaborate with various profiles:
other Ops as a rubber ducky, a mental support during an outage or simply to work in group.
ChallMakers to assist writing the scenarios in case of a difficulty or a specific infrastructure architecture or requirement.
Admins to report on the current lifecycle of the infrastructures, the incidents, or provide ideas for evolutions such as a partnership.
a technical leader to centralize the reflexions on architectures and means to enable the artistic direction achieving their goals.
Administrator
The Administrator is the showcase of the event. They take responsibility and decisions during the creation process of the event, make sure to synchronize teams throughout the development of the artistic and technical ideas, and manage partnerships if necessary. They are the managers through the whole event, before and after, not only during the CTF.
They basically collaborate with everyone, which is a double-edged sword: you take the gratification of the whole effort, but have no time to rest.